Warning: package 'ggplot2' was built under R version 4.5.2Warning: package 'tibble' was built under R version 4.5.2Warning: package 'tidyr' was built under R version 4.5.2Warning: package 'purrr' was built under R version 4.5.2This is a tutorial about how to “normalize” vowel formant data using data tools from the tidyverse. A lot has been written about vowel normalization (why we do it, how it should work, what methods are best) that I can’t really cover here, although Adank & Smits & Hout (2004) is often taken as the canonical citation, and I’ll be taking into account the recent “order of operations” from Stanley (2022).
There’s also a vowels R package (Kendall & Thomas 2018) that basically lets you run the NORM suite locally.
There are still many occasions when you might want or need to normalize your vowel data yourself, though, and learning how to do it is actually a great introduction to a number of tidyverse “verbs”, especially:
Since I’m focusing on how data structures relate to vowel normalization, I’ll cover 3 specific normalization procedures:
In terms of tidy data procedures, this is the simplest. All it requires is a group_by() and a mutate()
This procedure is a little more complicated, involving “pivoting” our data from wide to long, then long to wide again, using pivot_longer() and pivot_wider().
This method requires estimating by-speaker scaling factors (using group_by() and summarise()) then merging them back onto the original data (with left_join()).
To begin with, I’m going to import a few packages:
tidyverse: This is a “metapackage” that imports many different packages that contain functions we’ll need, including ggplot2
ggforce: This is a package that extends some of ggplot2’s functionality
khroma: This is another packages that has many different color palates for ggplot2.
joeyr: This is a package with functions written by Joey Stanley for vowel analysis.
Any time I use a function that’s not loaded by the tidyverse, I’ll indicate it with the package::function() convention.
Warning: package 'ggplot2' was built under R version 4.5.2Warning: package 'tibble' was built under R version 4.5.2Warning: package 'tidyr' was built under R version 4.5.2Warning: package 'purrr' was built under R version 4.5.2We also need to load in some data. Here are two tab-delimited files of Buckeye Corpus speakers whose interviews were run through FAVE.
s01_url <- "?meta:website.site-url/content/R/tidy-norm/data/s01.txt"
s03_url <- "?meta:website.site-url/content/R/tidy-norm/data/s03.txt"This code should load these files.
map_dfr thing did:
The map_dfr function iterated over each url, and applied the function read_tsv() to them. I had to tell read_tsv() that the column sex should be treated as a character data type, since the value f gets reinterpreted as FALSE otherwise. After reading in each tab-delimited file, map_dfr() then combines the results together row-wise, to produce one large data frame.
The variable vowels_orig is now one large data frame with both speakers’ FAVE output in it. Here’s three randomly sampled rows from each speakers’ data.
set.seed(50)
vowels_orig |>
group_by(name) |>
slice_sample(n = 3) |>
rmarkdown::paged_table()FAVE outputs a lot of useful information, but for this tutorial, I want to narrow down our focus to just a few columns
name: We’ll use this as a unique ID for each speaker
word: It’s just good to keep this info around
ipa_vclass: A column indicating each token’s vowel class in an IPA-like format
F1, F2: What we’re all here for. The first and second formants.
vowels_orig |>
select(name, word, ipa_vclass, F1, F2) -> vowels_focusvowels_focus |>
head() |>
rmarkdown::paged_table()First, let’s see how things look when we get our vowel means and plot them unnormalized. I won’t go into detail about how the plotting code works (see the LingMethodsHub tutorial on ggplot2 vowel plots).
vowels_focus |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1, F2), .fns = mean)) |>
ungroup() |>
ggplot(aes(F2, F1, color = name))+
geom_text(aes(label = ipa_vclass))+
ggforce::geom_mark_hull(aes(fill = name))+
scale_x_reverse()+
scale_y_reverse()+
khroma::scale_color_vibrant()+
khroma::scale_fill_vibrant()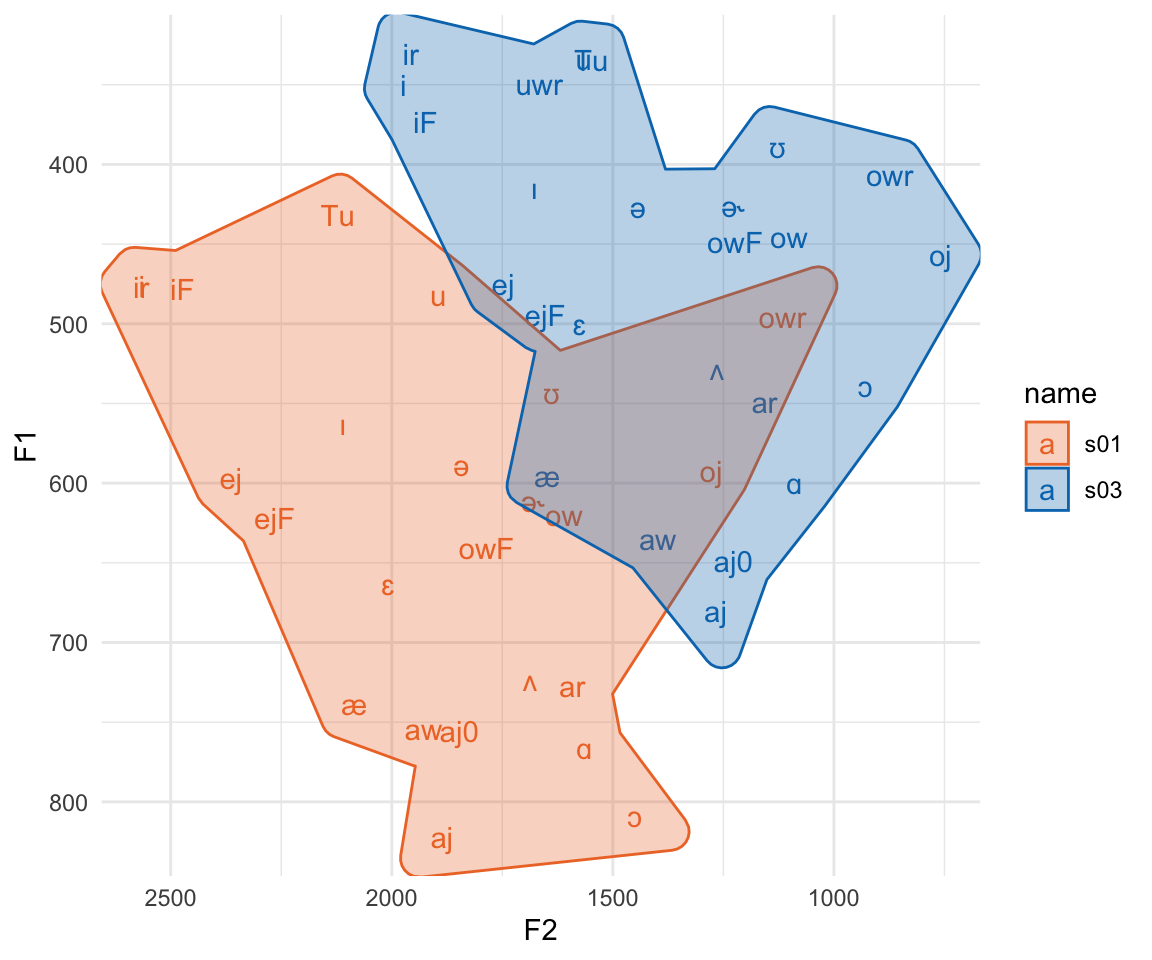
Here, we see reason number 1 why we’ll want to normalize vowels. These two speakers vowel spaced hardly overlap, but the relative position of vowel categories inside their spaces are fairly similar. All normalization methods try to do is pinch and scale appropriately to get the relative positions of these vowel spaces to overlap.
Another reason we might be motivated to normalize our data is because F2 has a much larger range of data than F1. We can more easily see that if we add coord_fixed() to the plot.
vowels_focus |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1, F2), .fns = mean)) |>
ungroup() |>
ggplot(aes(F2, F1, color = name))+
geom_text(aes(label = ipa_vclass))+
ggforce::geom_mark_hull(aes(fill = name))+
scale_x_reverse()+
scale_y_reverse()+
khroma::scale_color_vibrant()+
khroma::scale_fill_vibrant()+
coord_fixed()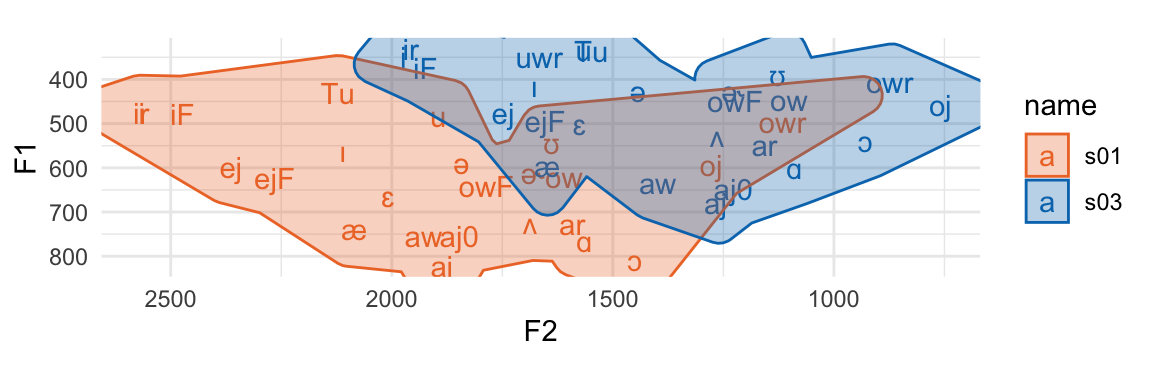
The plot is squished because F2 just has that much larger a range of values than F1. Any stats or calculations we do on vowels in the F1\(\times\)F2 space is going to be dominated by things that happen across F2 vs F1.
In order to get ready for normalization, I’m going to first filter out any vowel tokens that have a \(\sqrt{\text{mahalanobis}}\) distance from its vowel class greater than 2.
The first normalization procedure we’ll look at is “Lobanov” normalization (Lobanov 1971). An important thing to know here is that while phoneticians may call this procedure “Lobanov” normalization, the rest of the data analysis world calls it “z-score” or even just “standard score.”
The process works like this:
Within each speaker’s data ⤵️
Within each formant ⤵️
Since we already a have F1 and F2 separated out into separate columns, this means all we have to do us group_by() our vowels data by speaker ID (in name), then create our new normalized columns by subtracting the mean and dividing by the standard deviation.
The group_by(name) process in this pipeline means that when we calculate mean(F1) and std(F1) in the next part, those mean and standard deviation values are for each speaker’s subset of vowels_inlie.
Since z-scoring is so common a thing to do in quantitative analysis, R actually has a built in function, scale() that we could use instead of writing the math out ourselves.
Here’s the results of z-scoring! We’ve got largely overlapping vowel spaces now. The numeric values of these z-scores tend to run somewhere between -3 and 3 (less extreme for means). Both formants are also on the same scale, which you can see with the plot being roughly square shaped even with coord_fixed() being added.
vowels_zscore2 |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1_z, F2_z), .fns = mean)) |>
ggplot(aes(F2_z, F1_z, color = name))+
geom_text(aes(label = ipa_vclass))+
ggforce::geom_mark_hull(aes(fill = name))+
scale_x_reverse()+
scale_y_reverse()+
khroma::scale_color_vibrant()+
khroma::scale_fill_vibrant()+
coord_fixed()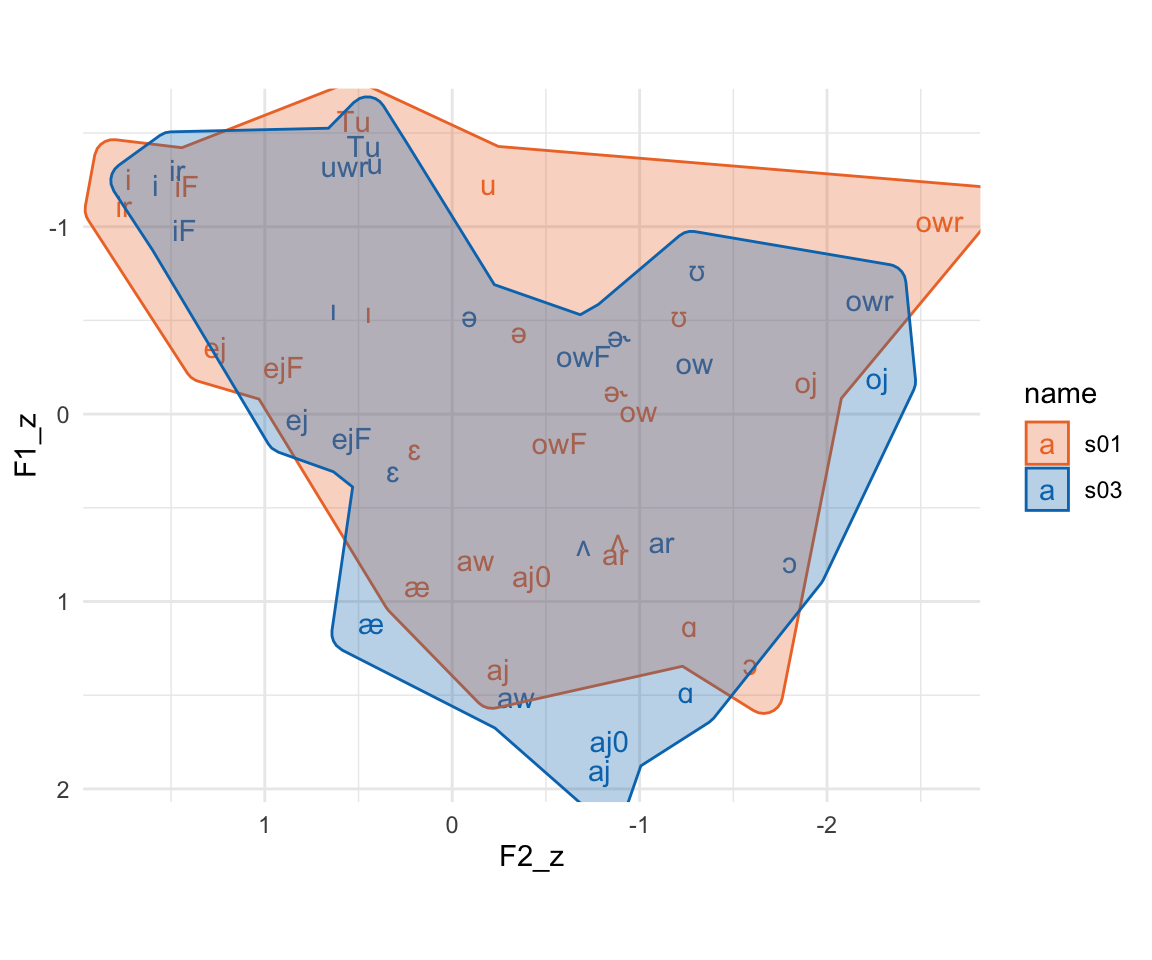
Next, we’ll look at what the vowels package calls “Nearey 2” normalization (Nearey 1978). The Nearey 1 procedure is more similar in terms of data code as z-scoring.1 The Nearey 2 procedure works like this:
Within each speaker ⤵️
Convert all formant measurements to log-Hz
Get the mean log-Hz across all measurements (F1 and F2 together)
Subtract the mean log-Hz from the log-Hz
“Anti-log” or exponentiate the result
We need to combine F1 and F2 measurements together to get their mean, and this is best achieved in the tidyverse by “pivoting” the data frame from wide to long. We’ll take it in steps. In each next step, I’m going to be putting additional tidyverse verbs between the data frame and the line that has head() |> rmarkdown::paged_table(), which is just there to provide nice looking output.
The vowels_inlie has data columns for the mahalanobis distance, which I want to drop off for now.
vowels_inlie |>
select(name, word, ipa_vclass, F1, F2) |>
# more verbs to go here
head() |> rmarkdown::paged_table()When we’re pivoting our data long and then wide again, we need to have a column that is a unique id for each vowel observation. I’ll create that with mutate(id = 1:n()) . The n() function there is a convenience function that returns the number of rows in each (group) of the data frame.
vowels_inlie |>
select(name, word, ipa_vclass, F1, F2) |>
mutate(id = 1:n()) |>
# more verbs to go here
head() |> rmarkdown::paged_table()Now, we want to take the F1 and F2 columns, and stack them one on top of each other, which we can do with pivot_longer(). This function needs to know at least three things:
Which columns are we going to be stacking on top of each other?
cols= argument.How should we keep track of the original column names?
names_to=.How should we keep track of the original values from these columns?
values_to=
vowels_inlie |>
select(name, word, ipa_vclass, F1, F2) |>
mutate(id = 1:n()) |>
pivot_longer(cols = F1:F2,
names_to = "formant",
values_to = "hz") |>
# more verbs to go here
head(12) |> rmarkdown::paged_table()You can get an idea for what pivot_longer() has done by comparing this table (Table 5) to the table before (Table 4). There are two rows in this long table for every row in the wide table. The name, word, ipa_vclass, and id values are repeated twice. There’s also a new formant column, which contains the column names we pivoted longer, and a new hz column, which contains the values from the columns we pivoted longer.
Now we can do the actual normalization. The column we’ll target is the new hz column. We’ll log it, subtract the mean log value, then convert it back to its original scale with exp(). And don’t forget we need to group_by(name) first too!
Technically, we’re done normalizing the formant data, but in order to make a nice F1\(\times\)F2 plot, we need to pivot the data wide again.
To do that, we first need to drop the hz column, because pivot_wider() will go weird if we don’t.2 Then, we need to tell pivot_wider() the following information:
Where should it get the names of new columns from?
names_from=
Where should it get the values to put into the new columns from?
values_from=
After this step, we’re done the normalizing process, so I’ll assign the result to a variable called vowels_neary
vowels_inlie |>
select(name, word, ipa_vclass, F1, F2) |>
mutate(id = 1:n()) |>
pivot_longer(cols = F1:F2,
names_to = "formant",
values_to = "hz") |>
group_by(name) |>
mutate(nearey = exp(log(hz)-mean(log(hz))))|>
select(-hz) |>
pivot_wider(names_from = formant, values_from = nearey) -> vowels_nearey
vowels_nearey |>
head() |> rmarkdown::paged_table()vowels_nearey |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1, F2), .fns = mean)) |>
ggplot(aes(F2, F1, color = name))+
geom_text(aes(label = ipa_vclass))+
ggforce::geom_mark_hull(aes(fill = name))+
scale_x_reverse()+
scale_y_reverse()+
khroma::scale_color_vibrant()+
khroma::scale_fill_vibrant()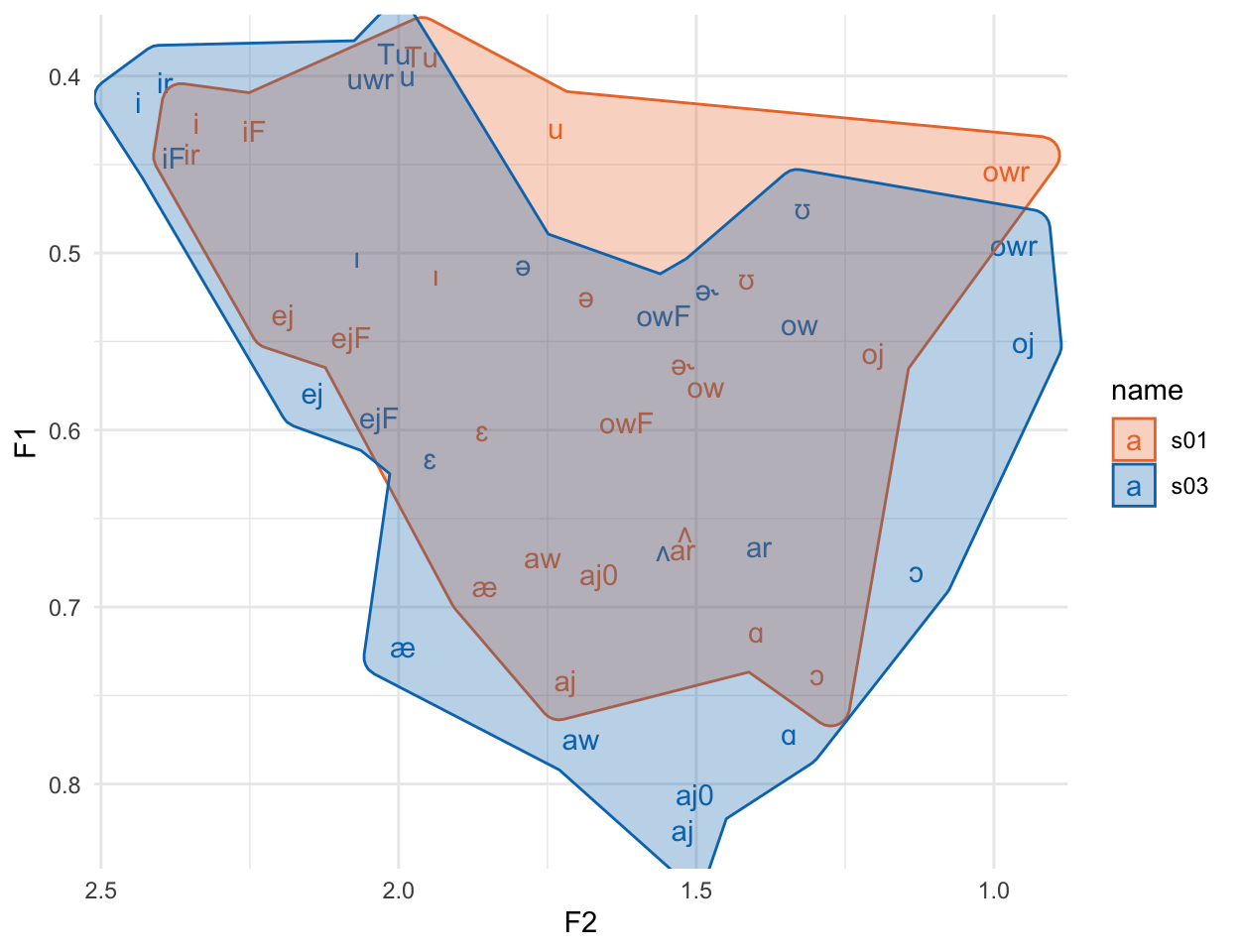
Again, the vowel spaces are largely overlapping. One thing that’s not immediately clear from this graph, though, is that this specific approach to Nearey normalization still has a much wider range for F2 than F1, which we can see if we plot it with fixed coordinates.
vowels_nearey |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1, F2), .fns = mean)) |>
ggplot(aes(F2, F1, color = name))+
geom_text(aes(label = ipa_vclass))+
ggforce::geom_mark_hull(aes(fill = name))+
scale_x_reverse()+
scale_y_reverse()+
khroma::scale_color_vibrant()+
khroma::scale_fill_vibrant()+
coord_fixed()
It gets better if we plot the log of the normalized values3, but then the vowel space doesn’t look like the familiar hertz space.
vowels_nearey |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1, F2), .fns = ~mean(log(.x)))) |>
ggplot(aes(F2, F1, color = name))+
geom_text(aes(label = ipa_vclass))+
ggforce::geom_mark_hull(aes(fill = name))+
scale_x_reverse()+
scale_y_reverse()+
khroma::scale_color_vibrant()+
khroma::scale_fill_vibrant()+
coord_fixed()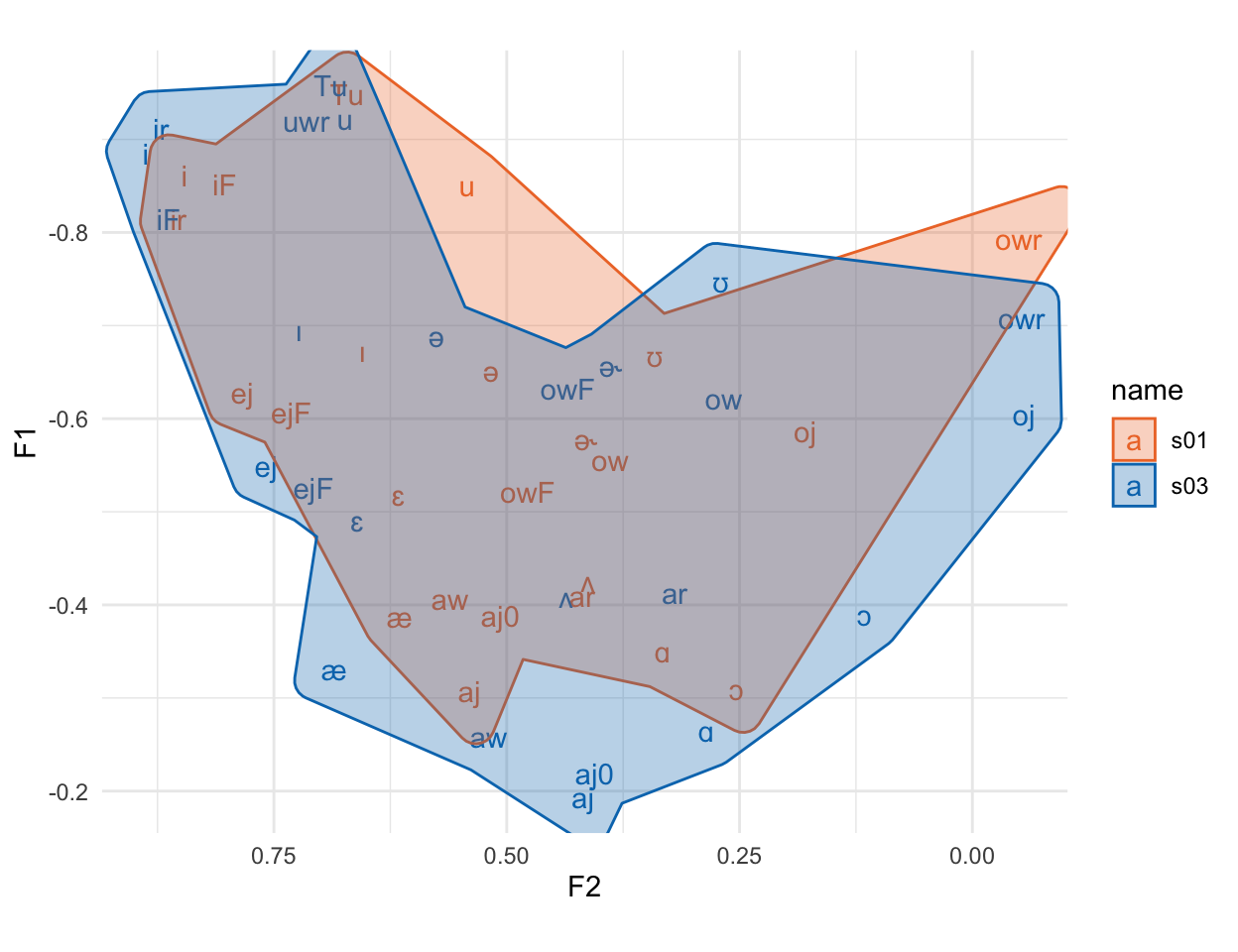
The final normalization method we’ll look at, which can’t easily be done with a single sequence of tidyverse verbs, is the Watt & Fabricius method (Watt & Fabricius 2002). The idea behind the Watt & Fabricius method is to define a vowel space triangle for each speaker, then to scale their formant values to the triangle.
I’ll follow the NORM suite and define the points of the triangle like so:
Top Left Corner, “beet” point: The F1 of the vowel with the smallest F1, and the F2 of the vowel with the largest F2
Bottom Corner, “bat” point: The F1 of the vowel with the maximum F1, and the F2 of that same vowel.
Top Right Corner, “school” point: F1 = F2 = “beet” point F1.
Here’s how you can get those values per speaker:
In order to plot these points in an F1\(\times\)F2 space, we need to do a little pivot_longer() and pivot_wider() again with the following steps:
pivot_longer(), to stack the values of the columns between beet_f1 and school_f2 on top of each other.
Split the point names (e.g. “beet_f1") into separate values (e.g. "beet" and "beet") using separate().
pivot_wider() using the column with "f1" and "f2" to make the new column names.
vowels_inlie |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1, F2), mean)) |>
group_by(name) |>
summarise(beet_f1 = min(F1),
beet_f2 = max(F2),
bat_f1 = max(F1),
bat_f2 = F2[F1 == max(F1)]) |>
mutate(school_f1 = beet_f1,
school_f2 = beet_f1) |>
pivot_longer(cols = beet_f1:school_f2, names_to = "var", values_to = "hz") |>
separate(var, into = c("point", "formant")) |>
pivot_wider(names_from = formant, values_from = hz) -> wf_points
wf_points |>
rmarkdown::paged_table()When we plot thee triangle points, we wind up with a plot that looks like a very simplified version of the vowel space from Figure 1.
wf_points |>
ggplot(aes(f2, f1))+
geom_polygon(aes(fill = name, color = name), alpha = 0.6)+
geom_text(aes(label = point))+
scale_x_reverse()+
scale_y_reverse()+
scale_fill_vibrant()+
scale_color_vibrant()
With the F1 and F2 of these triangle points, we then calculate scaling factors by just taking the mean of F1 and F2 for each speaker.
wf_points |>
group_by(name) |>
summarise(S1 = mean(f1),
S2 = mean(f2)) -> wf_scalers
wf_scalers |>
rmarkdown::paged_table()Now what we need to do is divide each speaker’s F1 and F2 value by these scalers. Right now the speakers’ original data is in vowels_inlie and the scaling values are in wf_scalers, so to do that division, we need to associate these two data frames.
Fortunately, both vowels_inlie and wf_scalers have a column name in common: the speaker ID column name. That means we can merge wf_scalers onto vowels_inlie with a join operation. There are a few different *_join() functions in the tidyverse, and here I’ll use left_join().
We need to tell left_join() the following information:
Which two data frames are we joining together?
|>, and the second data frame will be the first argument.Which columns should we use to join the data frames together?
left_join() will guess and try to join the data together using columns with the same name, but we can explicitly tell it which columns to use with the by= argument.vowels_inlie |>
left_join(wf_scalers, by = "name") |>
# more verbs to go here
# The group_by here is just to illustrate that each speaker's scalers were
# successfully merged
group_by(name) |> slice (1:3) |> rmarkdown::paged_table()Now all we need to do is divide F1 and F2 by their respective scaling factors to get the normalized Watt & Fabricius values.
vowels_inlie |>
left_join(wf_scalers, by = "name") |>
mutate(F1_wf = F1/S1,
F2_wf = F2/S2)->vowels_wf
vowels_wf |>
group_by(name) |> slice(1:3) |> rmarkdown::paged_table()vowels_wf |>
group_by(name, ipa_vclass) |>
summarise(across(c(F1_wf, F2_wf), .fns = mean)) |>
ggplot(aes(F2_wf, F1_wf, color = name))+
geom_text(aes(label = ipa_vclass))+
ggforce::geom_mark_hull(aes(fill = name))+
scale_x_reverse()+
scale_y_reverse()+
scale_color_vibrant()+
scale_fill_vibrant()+
coord_fixed()
Again, we’ve got largely overlapping vowel spaces, and since F1 and F2 were normalized separately, they’ve got very comparable data ranges.
There there has been a lot written about vowel normalization methods, and I’ve barely covered most of the relevant topics discussed in the literature. For example:
How well do these methods correspond to what listeners actually do when hearing people with different vowel spaces?
Should we really be plotting and analyzing formants in Hz, or should the by converted to a psychoacoustic dimension, like Mel or Bark?
Which method is the “Best”? What do we want a method to be “Best” at?
Instead, I’ve covered some of most commonly used normalization methods, and also tried to provide an outline of how these methods correspond to specific data frame operations in the tidyverse.
@online{fruehwald2022,
author = {Fruehwald, Josef},
title = {How to Normalize Your Vowels Using the Tidyverse},
series = {Linguistics Methods Hub},
date = {2022-10-20},
url = {https://lingmethodshub.github.io/content/R/tidy-norm/},
doi = {10.5281/zenodo.7232341},
langid = {en}
}